3D视觉系统技术方案详解,多场景应用或将引爆市场
2024-05-08 00:29:25
By: 迈尔微视
近年来,随着芯片技术的发展以及相关软硬件系统的深入,视觉传感器得到了极为广泛的应用。社会越来越智能,可以使用人工智能和大数据技术将人们记录下来的图像智能地利用起来,而不是用一个个柜子将图像、视频束之高阁。

从胶卷,到CCD 再到现在特别成熟、随处可见的CMOS,我们对图像传感器的性能追求也逐渐发生了改变。手机上开始出现前摄、后摄,后摄也出现了俗称的“浴霸”、“加特林”。在算法的加持下,每颗摄像头的用处都不一样。
而18、19年将是3D图像传感器起飞与腾飞的两年。有了3D传感器,我们就更容易做基于事件的分析并直接指导我们身边图像的优化做出体感游戏、人脸支付、机器人自动避障、工业自动分拣等应用。
2016年,AlphaGo成为第一个不借助让子而击败围棋职业九段棋手李世石的计算机围棋程序,这件事引起了人类的轰动,也展开了各种讨论。随之而来的是人工智能铺天盖地的宣传,这给了无数人信心,机器智能化的大浪潮扑面而来。
现在AI是一个很火的词。很多人都想做AI,也有很多人想往AI上面靠,AI的出现就相当于我们有了一个聪明的大脑。以前的处理器,只能处理一个特定场景的问题,AI给这个世界带来了可以自我学习、自我改进的功能,特别是对复杂场景的处理,AI更“聪明”。
可是只有AI,自动驾驶也做不起来,它还需要摄像头、激光雷达、毫米波雷达等各类传感器。
人脸识别也是非常好的一项技术,可以用来做人脸识别闸机、人脸无感支付,但是现在很多时候人脸识别还是容易受到环境干扰、黑客攻击。
所以,想把AI做好,传感器对我们进入智能时代至关重要。有了3D传感器,扫地机不会跌跌撞撞,仅凭一张照片一个视频也骗不开手机解锁,自动驾驶也能检测到来往行人、车辆,变得更安全。
3D传感器在AI几乎所有的领域都有广泛的应用,比如新零售,自动驾驶,个性化教育,智慧医疗,智能安防,智能监护,智能机器人等等。 2019年,我们也将迎来3D视觉技术在各个领域的广泛应用。
3D视觉技术方案
1、 双目视觉
谈到3D视觉,主要就是指图像不仅仅是二维的XY坐标,还要感受被拍照物体的距离远近,大小尺寸,也就是空间坐标Z。
我们人靠着左右两只眼可以估计出前方的门在3m处,桌子上的茶杯在1.5m处,远处的树大概在10m。仿生学是被应用得非常好的,通过两只摄像头,无人机可以精确分辨前方障碍物一根电线杆的距离。因为在它的左眼中,物体坐标为A,相应的视场角度α, 右眼坐标为B,相应的视场角度β,而基线距离x是早先就在机械结构上确定的。这样通过下面的公式,我们就可以得到空间点的z轴距离。
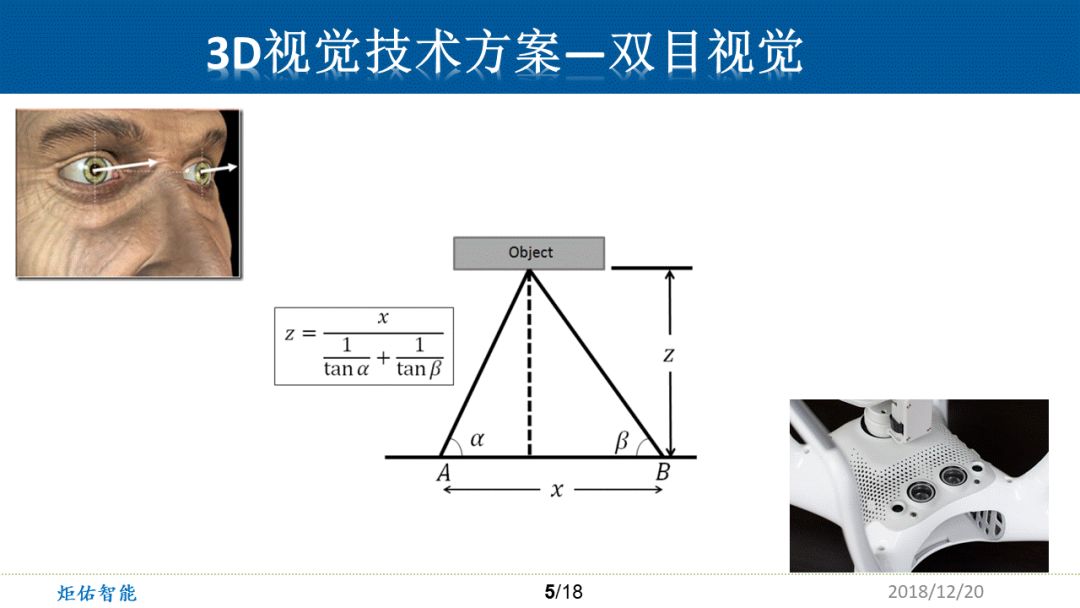
这个方法已经沿用了很多年,从技术上来说,视野里面所有的点都不可靠了,不能确定左右眼中的两个点是不是同一个点。它的优点就是观测距离远,精度高,成本相对较低。缺点就是面对单一场景,例如一面白墙,波动的水面,皑皑的白雪,绿油油的草地,我们人都会失去参考点,这时候无人机或处理器就无法计算出精确深度。
这也就是为什么双目摄像头鲜少应用在手机、人脸识别、人脸解锁等方面。
另外一个问题是,如果我们要将物体表面做一个高分辨率深度探测,那么处理器先要做多点的图像数据匹配,这个匹配算法的算力要求就超乎一般人想象,然后再执行图中公式的计算,而这个运算是三角函数级别,比较复杂。可以想象如果需要将人脸表面做1000个点的深度信息建模,那么所需要的运算量是多么的复杂。
2、结构光
2017年iPhone X面世,它采用3D结构光的方式,将我们人脸的3D数据测算出来,又一次引领了技术潮流。
对于结构光,其实也是一个很古老的技术,只不过苹果可以把它做到手机里面,还是比较让大家吃惊的。
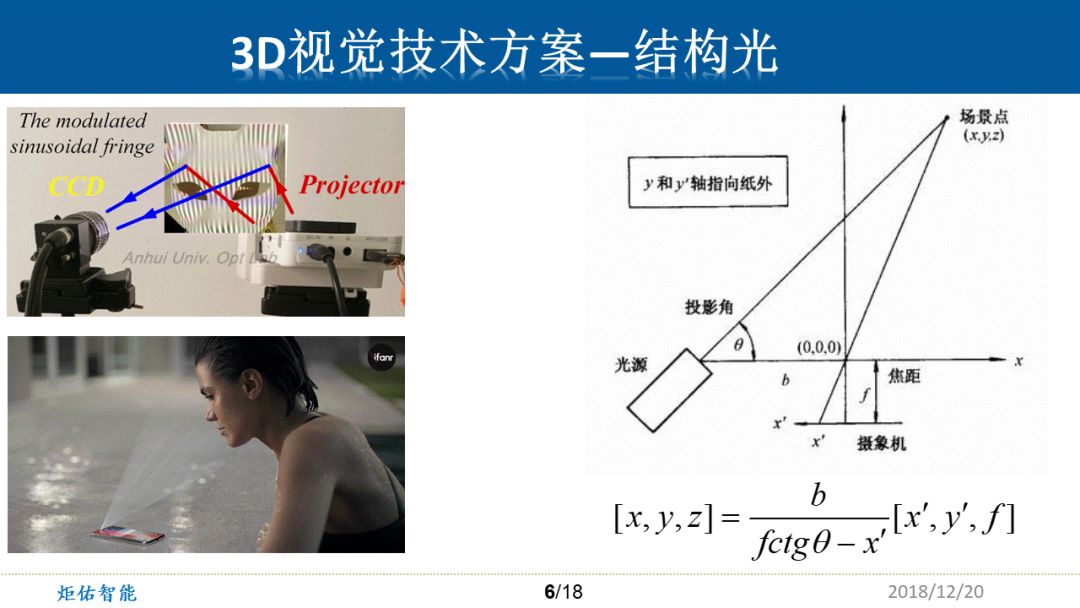
左图是一个3d结构光的简单实验版。通过右边的投影仪可以投影出黑白相间的条纹状图案,打在一个狐狸面具上面这些条纹状的图案就会产生一定的畸变。通过CCD相机将这个畸变的形状拍下来之后,便可以通过这个畸变的状态,去计算出这个面具相应的凹凸不平的3D信息。比如条纹向左弯曲,就代表凸起,向右弯曲代表凹陷。
单点结构光的三角测距法基本原理如右图,激光光源打出一个很小很亮的红点,传感器接收到之后,就可以在sensor表面找到这个特别亮的点的坐标(x’,y’)。结合光源的投影角,基线距离b,镜头焦距f,就可以通过上面的公式解析出三轴坐标(x,y,z)了。
而IPHONE X使用了3万个点的投射器,然后通过一百四十万像素的红外摄像头,将这些投射点的信息全部都采集回来,这中间一个最复杂的问题,就是要将这3万个点每一个点精确匹配。这里面最难的就是要精确找到打在脸上的点的精确ID,也就是得知道打出点的投射角,基线距离。这个匹配算法是需要非常大量的计算的。而且为了降低计算量,这3万个点的排布在我们看来是随机的,实际是符合某种数学几何规律的。
可以看到这个计算公式里面包含了各项几何参数,所以对组装工艺要求很高,而且后期客户将手机摔倒了或者震动,都可能会影响3D测量精度。
另外这块由于专利的保护,别人很难进入。所以业内对于苹果能推出这个方案,还是很佩服的,苹果还是具备相当强大的工程能力。因为IPHONE X的利润率不错,苹果可以做这块的事情。而别的厂商做这个就挺痛苦的,受限于成本和技术难度。
3、ToF
Time of flight,也就是飞行时间。最早的飞行时间是1638年伽利略做的一个实验。早前科学家们会为了解决测量光速而想了一系列的办法。

而现在我们采用这个原理,因为光速是已知的,且有很多近现代的精确的方法去测量。这时候只需要知道信号的延迟,就可以测量一个物体的精确距离。
举例说明,两纳秒的时间光飞行了60厘米。然后对于单纯的行程来说,也就是30厘米。可是如果要做人脸识别,或者要做一个避障的话,那基本上的最低要求就是在1厘米的范围内。到人脸识别可能要更高,比如3毫米。那么这个时间基本上就是在皮秒级。
这个方案的最大难度就是要控制电学系统以及光学系统做到非常高精度的计时。
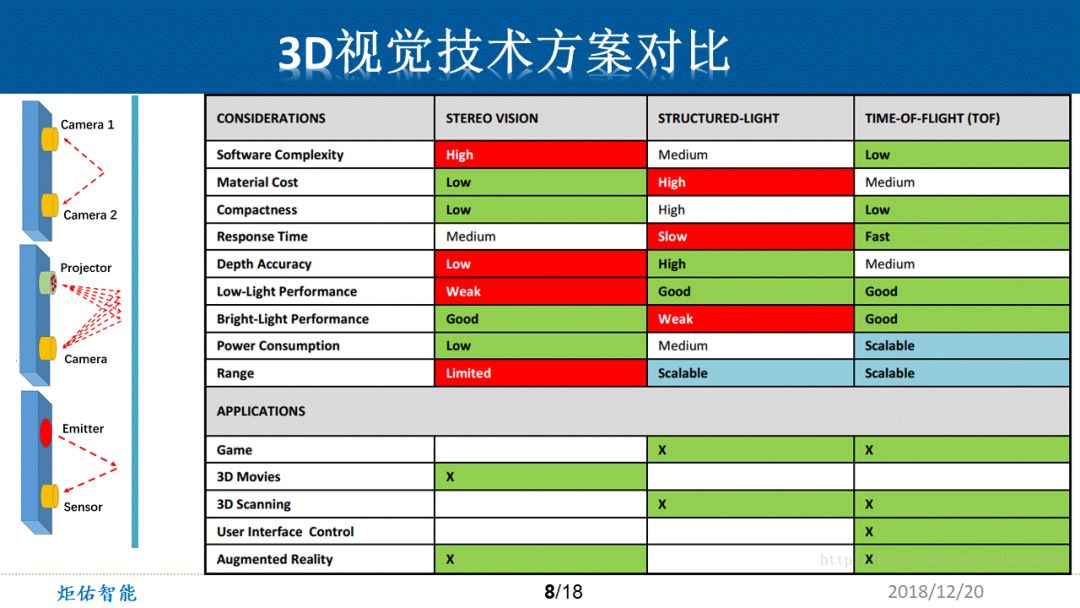
从软件的复杂度来说,双目视觉是最高的,因为它要在一个相对不确定性的图片上找到精确匹配的两个点。
从物料的成本上来说,结构光需要一个非常高的装配精度,这时候就会出现比较多的“废品”,综合来看,材料损耗是非常大的。而这两个问题,ToF都基本上以硬件的方法做了,所以这两点相对都会比较占优势。
既然ToF都已经做到了皮秒级和纳秒级的响应,那么无论是帧率还是处理速度,基本上都是凭借硬件的运算能力去决定,所以ToF可以做到非常高的帧率。
从测距精度来看,双目方案在碰到一些比较单调的物体的时候,基本上就没有办法再讨论精度的问题了;结构光在目前确实是相对精度比较高的,像一些工业的应用,可能现在还是以结构光为主;而ToF的测距精度有待于电学芯片提高时间测量精度,如果能够将皮秒级的延迟测量精确到飞秒级,那么ToF的测量精度又可以进一步的提高。
因为场景应用很复杂,例如,想在夜晚用3D摄像头时,那么双目就会比较困难,原因是它没有自己补光的补光灯。而结构光和ToF都是主动发光型的方案,所以在这一块,它们相对占优。
而在一个夏日炎炎的室外场景,太阳光中就包含了很多干扰光的能量。双目摄像头其实特别喜欢这种清晰的场景,但是结构光由于自己发出的光点容易被太阳的光淹没在噪声或背景光里,这时候就会影响它的分辨精度,甚至完全没办法测距。
而ToF采用的技术方案需要将光能量进行一个非常高频率的调制,这个调制光可以做到瞬间的能量超过太阳光,所以ToF对于太阳光的依赖性会大大降低。
从功耗上来看其实三者不会差别很大,ToF介于双目和结构光之间。但如果考虑到整体的3D视觉系统方案及处理器,ToF还是相对占优的,原因是运算量会大大降低。众所周知,现在的AI芯片即使再好,功耗其实相对来说很高的。
从探测的范围来看,如果要保持一个相对较高的精度,那么双目的探测范围就不会特别远,因为横向坐标差异一定要达到一个级别,才可以探测到比较远处的物体。而如果想看到100米,那么摄像头可能得有1600万或2000万像素。
结构光能看多远,主要取决于它的光点打在物体上,那个光点的能量是否能回到他的镜头。
而由于ToF采用了调制光的方法,可以将发光部分的能量提得相当的高。这时候,距离远近是可以根据场景来调节的。比如现在做到100米的激光雷达是很多的。而大家目前为止可能相对关注的一个指标,就是300米,能适用于高速路况的驾驶。
3D应用场景像3D电影这块是用双目摄像头去拍摄的,像3D的扫描现在用结构光和ToF比较多。然后像人脸识别、手势接近或手势识别这块,ToF应用也挺广泛的。AR和VR这块应用还有待3D空间场景建模好之后再行讨论。
迈尔微视3D解决方案
为大家讲解了TOF的工作原理——直接测距法。

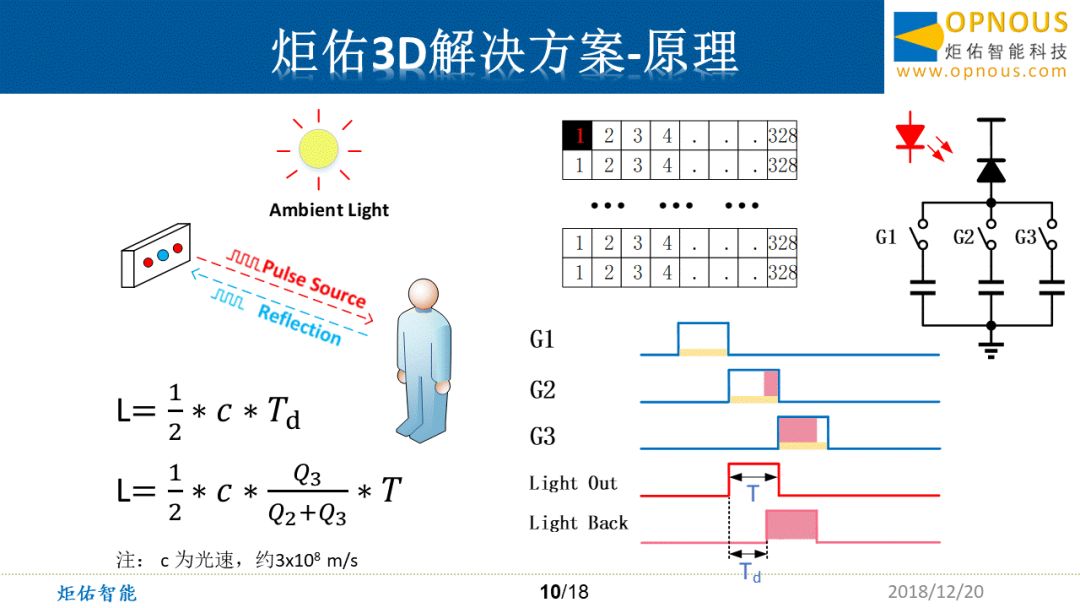
在迈尔微视的ToF模组上有一个激光器,在受电信号调制后会发出脉冲激光,激光打到物体上,会产生反射。然后使用我们的sensor接受光并测量返回光的延迟时间Td,乘以光速(c=3*108m/s),再除以2,就是单程的距离。在我们现有的QVGA sensor上有328*248个像素,每个像素底下有如右上角的像素电路,红色代表激光器,黑色代表一种光电转换器件。当接收到光之后,光电二极管就会将光转化为电子,当打开下面的任意一个开关之后,电子就会累积在下面的电容上,曝光结束后,我们会使用转换电路测量电容上的电压,经过一定的计算就可以得到深度图像了。
如何测距呢?像素下的每一个开关都是受到右下角的时序控制的,G1 G2 G3是三个开关的时序控制信号,每一个的脉宽是T,依次打开。在G2打开的同时,控制激光器同步发光,接收到的回光会有Td的延迟,就是粉红色面积的回光,因为G2 G3依次打开,这部分光转换的电子就被积累在G2 G3的电容上。大家可以看到,当距离越远,那么Td就会越大,那么G3收到的电荷就相比G2要多一些。最后依靠这个比例去计算时间。
不可避免地,传感器会受到外界环境中的杂光干扰,比如太阳光,日光灯光等等(图中黄色部分)。所以在激光器未发光的时候,使用G1去采集相同时间T的环境光,在G2 G3开启的时候,这些变化相对比较慢的环境光也会等量地被采集进来,如右下图中的黄色横条部分。最后,我们使用G2-G1, G3-G1去替换G2 G3,那么环境光就被消除了影响。当然,环境光还将在其他方面影响精度,以后有机会再探讨。
3D视觉在各方面应用

在日常聊天中,大家可能会觉得表情包不足以形容当下的心情——图不达意。在这个页面中,可以看到,做3D表情不用再去寻找笑脸,只要自己咧一下就可以了;测量家具只需要拿出手机,点两个点,就可以测量出一些物体的长宽高;在玩游戏时,里面人物的具体形态动态都可以通过摄像头实时捕捉自身形态,然后完成想要做的动作,这一点其实在Kinect已经有大量的应用。
而作为面对未来的技术,AR/VR/MR等等,其实都需要清晰的测量整个空间的3D结构、3D场景。如果建模做不好的话,那么会与人眼带来的真实感混淆,进而产生眩晕。

自动驾驶、智能车载也需要大量的3D传感器。左上图相当于HUD检测,需要对路面建模,不然箭头会发生偏颇。
左下图是控制音响音量时手指左转和右转都能检测到。其实大家有的会说,这一点普通的摄像头也可以做到。但是用ToF sensor就可以把它的背景分离,至少来说可以提高车载系统的稳定度及识别率,因为它提供了第三维的数据。
右上角是行人检测、行人识别,利用传感器可以控制自动驾驶车辆不会撞上玩耍中的小朋友。
右下角是一个智能倒车的事例。如果有3D ToF将倒车后视的整个场景建模,那么汽车就相对比较容易倒进比较狭窄或吵杂的环境,比人类做这些还是会高效很多的。
3D视觉在泛IoT里面还有更多更庞大的应用。比如说像正上方的空调,3D ToF在已知一定距离、发光能量的前提下,检测到接收回来的能量,就能测算出来这个人表面的反光率,比如红色这个人很热头上出汗了,那么检测到他头上反光率比较强,空调就会相应的改变方向对着他吹。而远处不太热的人就不会受到冷风的打扰。
而像智能助手、ARVR相关的游戏、智能零售服务机器人、智能门锁、智能试衣镜这些应用其实都是非常广泛的。
一些系统厂商会去做各种各样的应用方案,配合中国广大的消费市场。Franklin相信,泛IOT领域将会在2019年会有一个蓬勃的发展。

当然3D视觉系统也还有非常多的困难等着一项项解决。客户常常会有各种各样的想法,比如在室外用、在高速运动的物体上用、在自动驾驶上用等等。在现有的架构里面,客户当然就想要一个低成本、低功耗、高精度、小体积的方案,但是大家都知道,这个是比较困难的。
面对客户庞杂的需求,需要深入的了解并对客户做好分析。
迈尔微视会有能够支持到一些用户的使用场景,例如能够从电学的TX、RX芯片给大家做一些精确的分析,也能够配合自己的3D数据,做3D图像的优化,还有一些客户的3D应用,迈尔微视会提供一些算法建议。
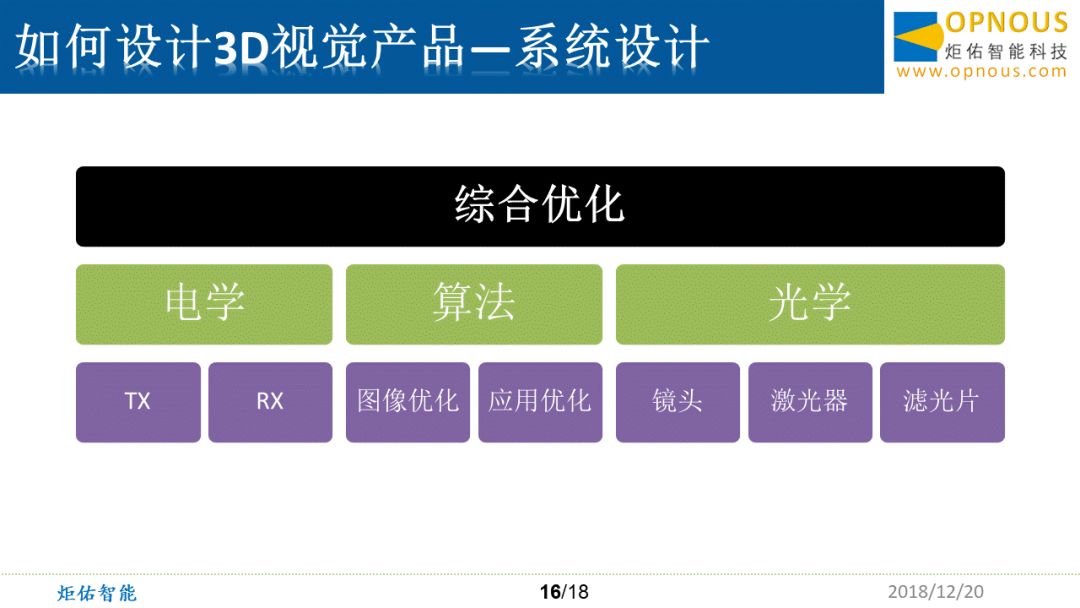
由此可见,3D视觉的产品,其实是一个相当综合性的学科,不仅包括电学的、算法的、光学的、还有一些机械结构的,用户心理等等,还有激光安全的法律或者一些条规的理解,所以需要系统性的做一个综合优化才能够给到市场一个合理满意的产品。

最后,Franklin引用了一个Yole的市场调研。对于2011到2023年的3D imaging&sensing的市场预测。可以看出,上升的曲线很明显,据专家预测大概在44%左右。Franklin表示这个市场应该更为乐观:“因为我们真的已经处于3D应用的爆发前期。”